Fedoraの変更点シリーズ
過去リリース分の記事は、以下のリンクを参照してください。
お伝えしたいこと
Fedora39のリリースノートを読んで、個人的に気になった項目をまとめます。
公式情報の見方
Fedora 39の変更点は、以下のリンクに載っています。
概要はリリースノートに、詳細情報はChange Setsのページに書いてあります。
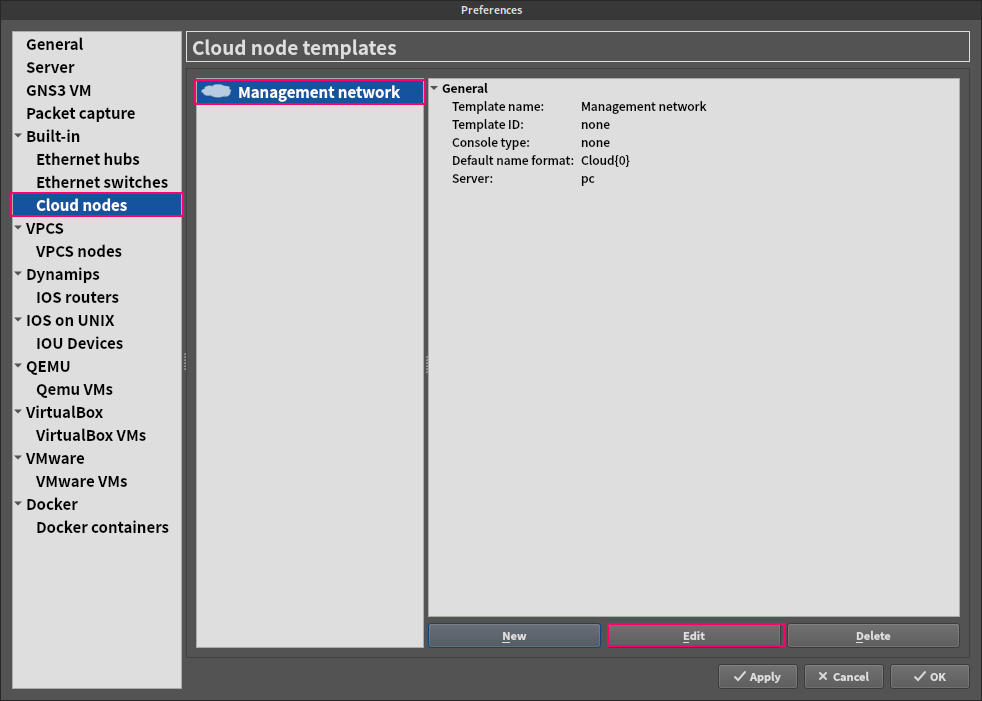
Change Setの各サブタイトルのリンクから詳細情報に飛べるようになっています (下図赤枠部)。
詳細を知りたい時に便利なので、こちらも活用ください。

Fedora39の既知の問題は、以下にまとめられています。
他バージョンのFedoraについて知りたい場合は、以下のリンクを参照してください。
- Fedora Docs - Fedora Linux User Documentation → 右上から該当バージョンを選択してRelease Notesのリンクに移動
- Fedora Wiki - Changes
Release Notes & Changes
Bashプロンプトに色がついた
Fedora 38以前ではBashプロンプトには色がついていませんでしたが、Fedora 39以降では色がつくようになりました。
また、直前のコマンドのExit Statusが0以外の場合にプロンプト文字列として表示されるようになりました。
↓従来のプロンプト

↓Fedora 39以降のプロンプト

なお、この色付けはログインシェルに対してしか適用されません。
具体的には、SSHでログインした場合には適用されません。
SSHでログインしたあと、更に手動でbashコマンドを実行すると適用されます。

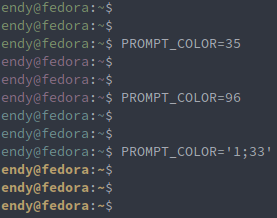
PROMPT_COLOR変数にカラーコードを入れることで、任意の色に変更できる作りになっています。
カラーコードの書き方はbash:tip_colors_and_formattingが参考になります。
以下の例では35がPurple、96がLight Syan、33がYellow、1がBold (太字) という意味になります。
SSHログイン時も反映したい場合は、以下のスクリプトを~/.bashrcに追記します。
sourceコマンドの後にPROMPT_COLORを変更してもしっかり反映される作りになっています。
source /etc/profile.d/bash-color-prompt.sh # PROMPT_COLOR=33
Bashプロンプト色付けの詳細
今回の変更は、Fedora39以降に初期インストールされているbash-color-promptというRPMパッケージによって導入されました。
rpm -ql bash-color-prompt、またはdnf repoquery -l bash-color-promptによってインストールされたファイル群を確認すると、/etc/profile.d/bash-color-prompt.shというシェルスクリプトが追加されていることがわかります。
シェルスクリプトの中身を見てみましょう。
if [ "$PS1" = "[\u@\h \W]\\$ " -a "${TERM: -5}" = "color" -o -n "${prompt_color_force}" ]; then PS1='\[\e[${PROMPT_COLOR:-32}m\]\u@\h\[\e[0m\]:\[\e[${PROMPT_COLOR:-32}m\]\w\[\e[0;31m\]${?#0}\[\e[0m\]\$ ' fi
ちょっと読むのが辛いかもしれませんが、最初のif文は以下の意味です。
PS1変数が初期値かつ、TERM変数がcolorで終わる場合 (手元の環境ではTERM=xterm-256colorでした)- または、
prompt_color_force変数が空ではない場合
そして条件にマッチしたとき、PS1を書き換えています。
PS1はBashの中で特殊な意味を持つ変数であり、この変数を書き換えることでプロンプト文字列を変更できます。
(参考) Bash Reference Manual - Controlling the Prompt
以上より、Bashにログインしたときに特定の条件を満たしていればプロンプトがカスタマイズされることがわかりました。
上記スクリプトは/etc/profile.d/配下に書かれているので、「bashログイン時」のみに実行されます。
そのためSSHログイン時も含めてbash起動時もプロンプト文字列を変更したい場合には、~/.bashrcをカスタマイズする必要がありました。
KickstartにDNS関連のオプションが追加された
Kickstartで以下のオプションを追加で使えるようになりました。
いずれもネットワークインターフェースに紐づけて設定するDNS関連のオプションです。
| オプション名 | 意味 |
|---|---|
--ipv4-dns-search |
|
--ipv6-dns-search |
|
--ipv4-ignore-auto-dns |
|
--ipv6-ignore-auto-dns |
|
EFIファイルシステムの最小サイズが200 MiBから500 MiBに拡張
マザーボードのファームウェアにBIOSではなくUEFIを使っている方に該当します。
ESP (EFI System Partition) という先頭に作られるパーティションのサイズが最小200 MiBから500 MiBに引き上げられました。
ファームウェア更新時に必要な空き容量が近い将来引き上げられることが背景にあります。
ESPの最大サイズは従来の600 MiBのまま変更ありません。
また、BIOSをお使いの方には影響ありません。
NetworkManager-initscripts-ifcfg-rhパッケージはFedora 41以降提供されない
この変更はNetworkManagerをGUI、nmcli、nmtuiなどで操作している方には影響ありません。
RHEL6時代まで続いたnetwork-scripts形式の設定ファイルを編集して運用している方に影響があります。
NetworkManager-initscripts-ifcfg-rhパッケージについて、詳細はFedora36の変更点 - /etc/sysconfig/network-scripts/ifcfg-* がデフォルト無効にを参照してください。
Python 3.12
Fedora 38ではPython 3.11系でしたが、Fedora 39系ではPython 3.12系が提供されるようになります。
Fedoraはリリースのたびに最新のPythonバージョンに追従することが基本ポリシーのようです。
(おそらく他の言語も同様ですが、Python以外はチェックしていません)
Bugs
f39タグ付きのCommon Issuesを確認しましたが、特に気になるものはありませんでした。
まとめ
興味を持ったトピック限定ですが、Fedora39の更新点をまとめました。