
前の記事
Fedora33以降より、systemd-resolovedがデフォルトで利用されるようになりました。
/etc/nsswitch.confがどのように変わったのか、記事の中で見比べます。
/etc/nsswitch.confがどのように変わったかについては、冒頭のサマリに書いてあります。
残りは参考情報です。
endy-tech.hatenablog.jp
お伝えしたいこと
Fedora33以降で/etc/resolv.confに代わってデフォルトのDNSクライアントとなったsystemd-resolvedについて概要を紹介します。
従来の/etc/resolv.confと比較して、systemd-resolvedは以下の特徴を持ちます。
- モダンなDNS機能に対応する
- D-Bus APIに対応し、NetworkManagerなどと連携して動作できる
- 名前解決結果をキャッシュできる
- hosts databaseのfiles, myhostname, dnsと同等の機能を持つ
- ドメイン名に応じたDNSサーバの使い分けができる (※)
(※) 一般にはSplit DNSとしばしば呼ばれる機能です。systemd-resolved用語ではper-link DNSやDNS Routingとも呼ばれます。本記事ではper-link DNSという用語を主に使います
systemd-resolvedの挙動を変更する方法は以下の通り複数あります。
今回は1のNetworkManagerを利用した方法を紹介します。
NetworkManagerを使ってネットワーク設定変更をするのがRHEL7以降の標準であり、馴染み深いと考えたためです。
- NetworkManagerを変更する。変更内容は、D-Bus経由でsystemd-resolvedに自動連携される (メモリ上のやり取り)
- systemd-resolved設定ファイルへの記述 (
/etc/systemd/resolved.conf)
- systemd-networkd設定ファイルへの記述 (
/etc/systemd/networkd.conf)
DNSサーバの指定方法は2つあります。
構成にもよりますが、前者の設定よりも後者の設定が優先されることがしばしばあります。
VPN利用環境など宛先ドメインによってDNSサーバを使い分けたい場合は、後者の宛先ドメインに応じたDNSサーバの設定を使う必要があります。
- Globalな設定
- 宛先ドメインに応じたDNSサーバの設定 (per-link DNS)
このように、systemd-resolvedの設定の記述場所は3パターンに分かれ、コンフィグも2パターンに分かれます。
これらを混在させても動作すると思うのですが、見通しを良くするためにもやり方を統一するのが良いと思います。
本記事ではNetworkManager経由で設定変更し、DNSサーバは後者の方法で指定する方法に統一します。
特にDNSサーバの決定は、DNS Default Routeを利用します。
詳細はper-link DNSの#基本動作の要点で説明します。
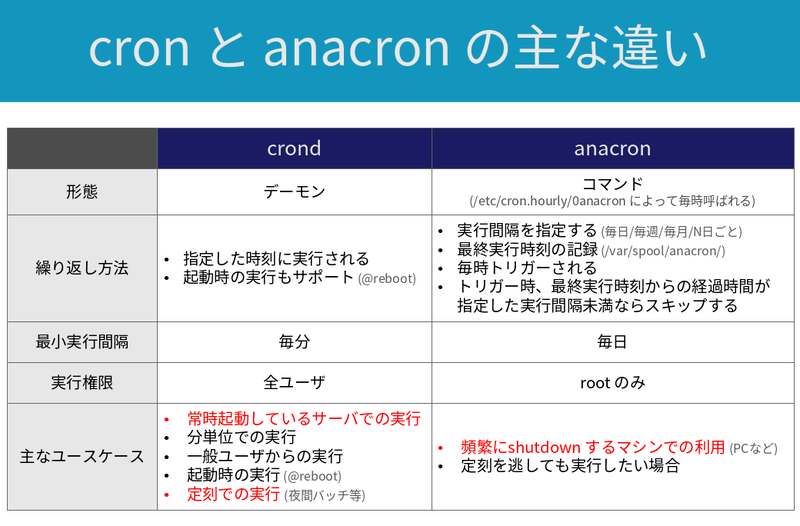
systemd-resolvedとは
systemd-resolvedは、Linux においてDNSクライアントとして動作します。
多くのLinuxディストリビューションでinitプロセスを管理しているsystemdの1コンポーネントでもあります。
systemd-resolvedの主要な構成要素は、下表の通りです。
systemd-resolvedのAPI
systemd-resolvedと外部アプリケーションを連携させる手段 (API: Application Programming Interface) は3種類あります。1,2
いずれのAPIもローカル専用で、ネットワーク越しに外部ホストからアクセスすることはできません。
サポートされる機能の多さとしては(1) > (2) >> (3)という関係になっており、systemdの開発者としては(3)よりも(1), (2) のAPIを使うことをより推奨しています。
(3) は、古いプログラムへの互換性を保つために残されています。
次のセクションでこれらのAPIがどのような使われ方をするのか、より具体的に紹介します。
| # |
API |
説明 |
| 1 |
D-Bus (Desktop Bus) |
プロセス間通信機能を提供するAPI |
| 2 |
NSS (Name System Switch) |
/etc/nsswitch.confを介してアクセスする方式。
GNU C ライブラリによって実装されている |
| 3 |
Local DNS Stub Listener |
TCP/UDP の 127.0.0.53:53 でリッスンしている
/etc/resolv.confを直接参照するプログラムが利用する |
(1) D-Bus (Desktop Bus)
プロセス間で各種設定情報や命令を直接やり取りするための仕組みです (IPC: InterProcess Communication)。
D-Busは、同一OS内のローカルのやり取りのみをサポートします。
ネットワーク越しに外部ホストとメッセージをやり取りするような使い方はサポートされていません。
ユーザーがD-Busに対応したアプリケーションを操作すると、D-Bus API経由で関連するプロセスに情報を伝達して動作に反映します。
D-Busの情報のやり取りはプロセス間で行われるので、ユーザーがD-Busの動きを意識することは基本ありません。
D-Busは、いわば「アプリケーションの作り込み」に相当する領域です。
D-Busの概要は、下記サイトにとてもわかりやすく解説されていました。
www.silex.jp
D-Busを利用している身近な例としては、私の知る限り2つあります。
どちらもNetworkManager関連です。
1つ目は、nmcliです。
nmcliで設定する際、裏ではNetworkManager.serviceの D-Bus API を叩いて設定変更を反映しているようです。
※nmtuiなど、その他のコマンドも恐らく同様です
以下の出力からも何となく察せると思います。
nmcli conn up eno1
2つ目は、NetworkManagerからsystemd-resolvedへの設定情報連携です。
具体例としては、NetworkManagerでDNSサーバのIPアドレスを変更したら、D-Bus経由でsystemd-resolved側でもDNSサーバを変更するといったものが挙げられます。
NetworkManagerからsystemd-resolvedにD-Bus連携する設定は、/etc/NetworkManager/NetworkManager.confのsystemd-resolvedというパラメータです3。
デフォルト値はtrueで、systemd-resolvedにD-Bus API経由で設定情報を連携するようになっています。
つまり、NetworkManagerのDNS設定を変更すると、systemd-resolvedにも動作が反映されます。
NetworkManagerとsystemd-resolvedの連携については、(参考) 具体例にて実機操作のサンプルを示します。
(2) NSS (Name Service Switch)
Linuxの多くのプログラムは、FQDNやホスト名をIPアドレスに名前解決する際に/etc/nsswitch.confのhosts:行を参照します。
RHEL7とRHEL8は/etc/resolv.confに従ってDNSサーバを決定します。
Fedora33以降は、systemd-resolvedに従ってDNSサーバを決定します。
/etc/nsswitch.confの中身や具体的な挙動について、詳細は前回記事の/etc/nsswitch.confのhosts行を理解するを参照してください。
(3) Local DNS Stub Listener
Local DNS Stub Listener とは、TCP/UDPでリッスンしている 127.0.0.53:53のことです。
Fedora33以降では/etc/resolv.confが/run/systemd/resolve/stub-resolv.confへのシンボリックリンクとなっており、/run/systemd/resolve/stub-resolv.confをsystemd-resolvedが自動更新するという構造になっています。
結果として、/etc/resolv.confを参照すると、システムのDNSサーバが127.0.0.53、つまりsystemd-resolvedに設定されていることになります。
digコマンドやhostコマンドのように、/etc/nsswitch.confではなく/etc/resolv.confを直接参照するプログラムにも互換性を持たせるため、こういったアクセスの仕方も用意されています。
ちなみに、/runはtmpfsという仮想メモリファイルシステムをマウントしています。
/runはメモリ上にあるデータということですね。
このあたりが気になる方は、man tmpfsをご覧ください。
systemd-resolved の基本機能
前回記事の/etc/nsswitch.confのhosts行を理解するで紹介しましたが、名前解決の手段 (NSS用語でservice、またはservice specificationと呼ばれます) は1つではありません。
systemd-resolvedが導入される前は、少なくともfiles (/etc/hosts)とdns (/etc/resolv.conf)がありました。
resolve (systemd-resolved) は、既存のserviceと同等の機能を持ちます。
resolveは、下表の全てのserviceと同じ機能を提供します。
| service |
機能 |
files |
/etc/hosts |
mdns4_minimal |
mDNS機能 (※) |
dns |
/etc/resolv.conf |
myhostname |
自身のホスト名やデフォルトゲートウェイなどの名前解決 |
(※) systemd-resolvedはmDNS機能をデフォルトで無効化しているが、後から有効化できる
既存の機能と比べて、systemd-resolvedはより多機能かつ高効率です。
具体的にはDNSSecやper-link DNS機能に対応し、過去の名前解決結果をキャッシュに保持します。
以降のセクションでは、systemd-resolvedのDNSサーバによる名前解決機能 (/etc/resolv.conf相当) に着目し、更に詳しく説明します。
systemd-resolvedと/etc/resolv.confの違い
Fedora Wiki - Changes/systemd-resolvedの内容を参考にしつつ、systemd-resolvedと/etc/resolv.confの主な違いを紹介します。
標準化
Ubuntuなど、最近のディストリビューションは、systemdのコンポーネントを活用する方向にシフトしてきています。
systemd-resolvedを使うことで、Red Hat系のディストリビューションも他のディストリビューションとの挙動差異が埋まります。
動的な挙動変更
/etc/resolv.confに記述可能なオプションは限定的で、対応していない機能がいくつかありました。
また、NetworkManagerとの連携方法も限定的なものでした (※)。
(※) D-Busにはもちろん対応していませんでした。/etc/resolv.confをシンボリックリンクとし、シンボリックリンク先をNetworkManagerが自動更新することで連携していました。これは、systemd-resolvedが非推奨としている#Local DNS Stub Listenerに相当する連携方法です。
systemd-resolvedは、/etc/systemd/resolved.confだけでなく、D-BuS APIの連携によって他プロセスときめ細かに連携できます。
ステータスは設定ファイルのみに縛られず、柔軟かつ動的に挙動を変えます。
一方で、設定ファイルだけでは現在のステータスが読み取れないという特性もあります。
その点は、resolvectlというコマンドが解決してくれます。
resolvectlによってステータスを確認したり、DNSクライアントとしての一部の挙動を変えることも可能です。
resolvectlの利用例については#(参考) 具体例で、主なコマンドについては[#resolvectl]で紹介します。
search (ドメイン自動補完)
まずは、search機能についておさらいします。
例えばsearch に xxx.com を指定していたとします。
ping Aを実行すると、Aが名前解決できなくてもxxx.comを自動補完してA.xxx.comにpingを実行してくれます。
従来のDNSでは、/etc/resolv.confのndotsというオプションによって「ピリオドをいくつまで含んでいるときに自動補完の対象とするか」を制御できました4。
systemd-resolvedの場合はndotsを敢えて実装しておらず、単一ラベル (ピリオドを含まない名前) の場合のみドメインを補完します5。
systemd-resolvedがndotsを実装していない理由は、「既にトップレベルドメインは1500以上存在し、常々増加している。新しいトップレベルドメインが生まれたことで、ndotsに依存した名前解決が不意に失敗する可能性を危惧したため、ndotsを無効化した」と書かれています6。
DNSサーバの複数指定
従来のDNSでは、最大3台までDNSサーバを指定できます。
基本的には1台目のみにクエリを投げます。
1台目のDNSサーバへのクエリがタイムアウトしたら、次のDNSサーバに問い合わせます。
systemd-resolvedでは、Routing という仕組みによってDNSサーバが選択されます。
ネットワークのIP Routing とは若干関係ありますが、完全に別物です。
詳細は、次セクションの#per-link DNS (Routing)で紹介します。
per-link DNS (Routing)
基本動作
systemd-resolvedは、ネットワークインターフェースごとにDNSサーバを指定できます。
その上で、Routing という仕組みによって、クエリごとにDNSサーバを使い分けます。
具体的には以下の動きになります7。
(※) グレーにした部分はあまり重要ではないので、読み飛ばして結構です
(※) 下表の項番5については一部ドキュメントに書かれていない情報もありますが、私の手元で検証済みです。長くなってしまうので、エビデンスは掲載していません
(※1) man resolv.confのDomainsに関する説明も参照
(※2) search domains に ~. を指定することで、どのFQDNにもマッチする指定が可能です (DNS Default Route)。best matching の観点では、最も優先順位が低いです。~をつけるとRouting Domain の扱いとなり、「DNS Routingの評価対象になるが単一ラベルに対するドメイン補完には利用されない」挙動になります。.はルートドメインを意味し、全てのドメインにマッチします
(※3) グローバルなDNS設定 (/etc/systemd/resolved.confのDNSやDomains) もper-link DNSと同様に評価されます。グローバルなDNSサーバがbest matching となれば、グローバルなDNSサーバのみにクエリされます。グローバルなDNSサーバとper-link DNSサーバの両方がbest matching となった場合は、どちらにもクエリされます
(※4) 例えば、www.google.comというFQDNにはwww、google、comという3つのラベルが含まれます
基本動作の要点
DNS Routing の挙動が非常にややこしいですが、上表の4と5をまとめると、A, AAAA, PTR レコードのクエリ先のDNSサーバは、以下の順序で評価されるようです。
あらゆる状況に対処できるように、systemd-resolvedには細かいルールが設定されていますが、基本的には1か2で確定できるように設計するのがわかりやすくてオススメです。
~.を含め、search domains に一致したDNS (best matching)。per-link DNS もグローバルなDNSも特に差はなく、同列に評価される- グローバルなDNSが設定されていれば、そこにクエリする
- IP Routing の世界でデフォルトルートと紐づくNICにper-link DNSサーバが設定されていれば、そこにクエリする
- 全てのper-link DNSサーバにクエリする
設定方法
per-link DNSの設定方法は、私の知る限り以下の3つがあります。
なお、/etc/systemd/resolved.confではGlobalな設定としてDNSサーバを指定できますが、 per-link DNSの指定はできません。
このことは、man resolved.confの以下のような表現から読み取れます。
per-link DNS servers acquired from systemd-networkd.service(8)
or set at runtime by external applications.
本記事では、使い慣れたnmcliを使用します。
今後ネットワーク設定の標準がNetworkManagerからsystemd.networkdに変更されることがあれば、systemd.networkdの設定ファイルの挙動を別途検証するかもしれません。
しかし、今のところその予定はありません。
(参考) 具体例
実際にDNS設定がどうなるか、色々な例で試してみました。
systemd-resolvedで/etc/hostsを使用する
/etc/hostsに試験用のエントリを追加します。
8.8.8.8 google-hosts
この状態で、以下のコマンドを実行します。
getentは、NSS (/etc/nsswitch.conf)を参照して名前解決を行うコマンドです。
-sによってresolve serivce、つまりsystemd-resolvedを指定しています。
以下の通り、systemd-resolvedが/etc/hostsの内容にしたがって名前解決をしていることがわかりました。
getent -s resolve hosts google-hosts
別の方法として、resolvectl queryによってsystemd-resolvedによる名前解決を行うことでも確認できます。
resolvectl query google-hosts
検証が終わったので、/etc/hostsを元の状態に戻しておきます。
search domains にヒットする方を優先する
こちらの構成で検証します。
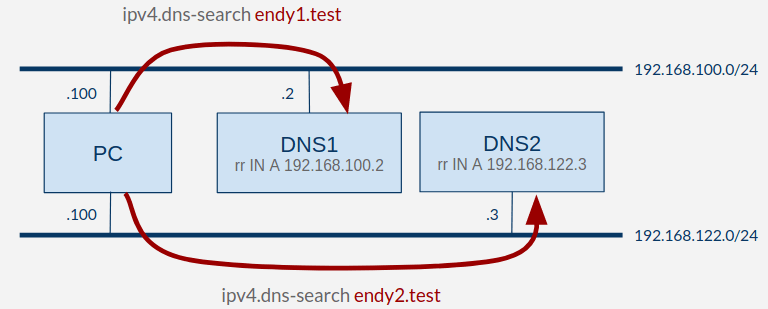
DNS1, DNS2 という2台のDNSサーバを用意し、PCからそれぞれにクエリを投げて名前解決する構成を組みました。
PCには、DNS1と紐づけてendy1.testを、DNS2と紐づけてendy2.testを search domains (ipv4.dns-search) に設定しています。
systemd-resolvedにおいて、問い合わせ先のDNSサーバは search domains に一致するものが優先される仕様です。
rr.endy1.testはDNS1に、rr.endy2.testはDNS2に問い合わせる構成となります。
PCのNetworkManager設定は、以下のようになっています。
nmcli connection add \
con-name dnstest1 \
ifname enp7s0 \
type ethernet \
ipv4.method manual \
ipv4.addresses 192.168.100.100/24 \
ipv4.dns 192.168.100.2 \
ipv4.dns-search endy1.test
nmcli connection up dnstest1
nmcli connection add \
con-name dnstest2 \
ifname enp1s0 \
type ethernet \
ipv4.method manual \
ipv4.addresses 192.168.122.100/24 \
ipv4.dns 192.168.122.3 \
ipv4.dns-search endy2.test
nmcli connection up dnstest2
DNS1には、 endy1.test.zoneとendy2.test.zoneには、それぞれ以下の行を記載しました。
rr.endy1.test、rr.endy2.testに、それぞれ192.168.100.2 (DNS1のIPアドレス) を紐づけました。
ゾーンファイルを2つ作ったのは、ドメイン名を区別するためです。
rr A 192.168.100.2
DNS2には、 endy1.test.zoneとendy2.test.zoneには、それぞれ以下の行を記載しました。
rr.endy1.test、rr.endy2.testに、それぞれ192.168.100.2 (DNS2のIPアドレス) を紐づけました。
DNS1とは異なるアドレスを返すため、どちらにPCからDNS1とDNS2のどちらに問い合わせたかわかるようになっています。
rr A 192.168.122.3
ここで、PCから2箇所にDNSクエリを投げてみます。
endy1.testはDNS1に問い合わせており、endy2.testはDNS2に問い合わせていることがわかります。
この挙動から、 search domains と紐づくDNSサーバに優先して問い合わせることがわかります。
dig rr.endy1.test | sed -ne '/ANSWER SECTION/,/^$/p'
dig rr.endy2.test | sed -ne '/ANSWER SECTION/,/^$/p'
resolvectl domainでsystemd-resolvedが選択するリンクと search domains の関係を確認すると、以下のようになります。
resolvectl domain
best matching が優先される (longest match)
黄色の部分のみ構成を変更しました。
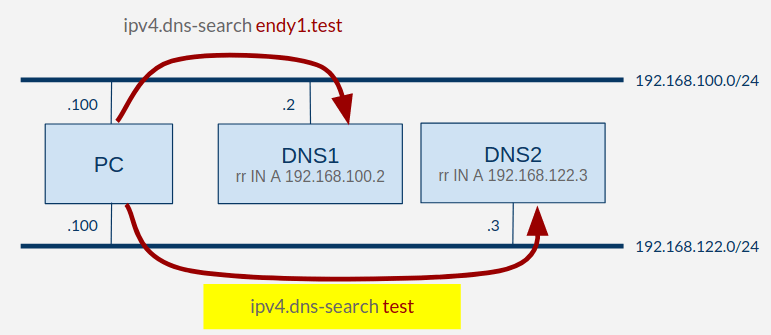
rr.endy1.test、rr.endy2.test共に、.testドメインに属します。
ただ、上図の構成においては、仕様上以下の動作になります。
rr.endy1.testはDNS1とDNS2の両方の search domains に該当するが、best matching の考え方に基づいて2階層分のドメイン名に一致するDNS1が優先されるrr.endy2.testは、DNS2の search domains にしか一致しないため、DNS2が優先される
黄色部分の変更差分のNetworkManager設定は、以下のようになります。
sudo nmcli connection modify dnstest2 ipv4.dns-search test
sudo nmcli connection up dnstest2
ここで、PCから2箇所にdigを実行してみます。
endy1.testはDNS1に問い合わせており、endy2.testはDNS2に問い合わせていることがわかります。
この挙動から事前の予想通り、より多くの label (ピリオドで区切られた文字列) に一致するDNSサーバが優先されることがわかりました。
dig rr.endy1.test | sed -ne '/ANSWER SECTION/,/^$/p'
dig rr.endy2.test | sed -ne '/ANSWER SECTION/,/^$/p'
resolvectl domainでsystemd-resolvedが選択するリンクと search domains の関係を確認すると、以下のようになります。
resolvectl domain
best matching なDNSサーバが複数存在する場合、全てのDNSサーバにクエリする
次は以下の黄色部分を変更しました。
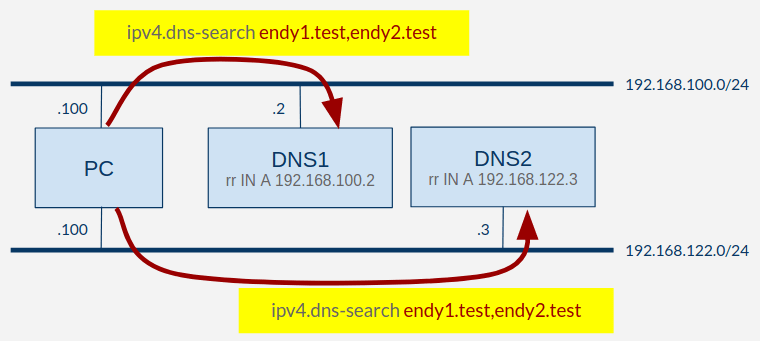
search domains の条件を両方のリンクで揃えました。
search domains のbest matching でも同等な場合は、それらのDNSサーバ全てに問い合わせる仕様です。
そして、最初にDNS応答を受信した経路が採用されます。
NetworkManagerの設定差分は、以下のようになります。
sudo nmcli connection modify dnstest1 ipv4.dns-search endy1.test,endy2.test
sudo nmcli connection up dnstest1
sudo nmcli connection modify dnstest2 ipv4.dns-search endy1.test,endy2.test
sudo nmcli connection up dnstest2
dig で確認します。
DNSキャッシュをクリアしながら実行していると、途中で結果が変わっていることがわかります。
DNS1とDNS2のうち、先に受信した応答が表示されています。
どちらもほぼ同時に応答を受信するため、結果が不定になっています。
dig rr.endy1.test | sed -ne '/ANSWER SECTION/,/^$/p'
dig rr.endy2.test | sed -ne '/ANSWER SECTION/,/^$/p'
resolvectl flush-caches
dig rr.endy1.test | sed -ne '/ANSWER SECTION/,/^$/p'
dig rr.endy2.test | sed -ne '/ANSWER SECTION/,/^$/p'
最後に、resolvectlで設定を確認します。
両方の search domains にbest matching となっていることがわかります。
resolvectl domain
DNSデフォルトルート
DNSデフォルトルートの挙動を確認します。
DNS1と紐づくリンクに、デフォルトゲートウェイを設定します。
また、 search domains を空欄にすることで一致しないようにします。

search domains に具体的なキーワードが全く該当しない場合、デフォルトルートが評価されます。
以下の2通りのいずれかの条件に該当するリンクは、デフォルトルートとして扱われます。
- IPルーティングのデフォルトゲートウェイと紐づくリンクであること
- search domains に
~. が含まれること (※)
(※) .は、ルートドメインなので全てのドメインに一致します。また、ドメイン名の先頭に~を付けると、「ホスト名にドメイン名を補う」効果はなく、「best matchingなDNSサーバの選択」のみに寄与するという意味になります (routing domain)。
即ち、今回の場合は全てのクエリがDNS1を向くようになります。
NetworkManager上は、以下の変更差分となります。
sudo nmcli connection modify dnstest1 ipv4.gateway 192.168.100.1
sudo nmcli connection modify dnstest1 ipv4.dns-search ""
sudo nmcli connection up dnstest1
sudo nmcli connection modify dnstest2 ipv4.dns-search ""
sudo nmcli connection up dnstest2
digを実行してみると、実際に全てのクエリがDNS1を向くようになります。
dig rr.endy1.test | sed -ne '/ANSWER SECTION/,/^$/p'
dig rr.endy2.test | sed -ne '/ANSWER SECTION/,/^$/p'
resolvectl domainからは、両リンクで search domains が空っぽであることがわかります。
resolvectl dnsの出力では、実質的にDNS1にしか問い合わせが向いていないことを反映して、DNS1のみが表示されます。
resolvectlからは、IPルーティングのdefault routeが反映されて、DefaultRouteのフラグが片方のリンクで有効 (+) になっていることがわかります。
resolvectl domain
resolvectl dns
resolvectl
長くなるのでコマンド実行結果は省きますが、いくつか追加で補足します。
DNS2の search domains に~.を追加すると、IP Routing のデフォルトゲートウェイよりも優先されてDNS2のみに問い合わせるようになります。
NetworkManagerの設定コマンドとしては、以下のようになります。
sudo nmcli connection modify dnstest2 ipv4.dns-search "~."
sudo nmcli connection up dnstest2
更にDNS1の search domains に~.を追加すると、DNS1とDNS2の両方にクエリを出すようになりました。
search domains に~.が設定されたリンク同士であれば、ipv4.gatewayの設定有無が優先順位に影響することは無いようです。
resolvectl
systemd-resolvedは、/etc/systemd/resolved.confやデフォルトルート、他デーモンからのD-Bus連携によって挙動が変わるため、非常に複雑です。
resolvectlコマンドを使えば、systemd-resolvedの設定情報を確認できるため便利です。
また、このコマンドはDNSキャッシュクリアにも使えます。
コマンドの詳細は、下表のとおりです。
| コマンド |
詳細 |
resolvectl status |
グローバルな設定の表示。
resolvectlでも同じ |
resolvectl domain |
per-link DNSと関係する search domains の表示 |
resolvectl dns |
各リンクと紐づくDNSサーバの表示 |
resolvectl query <domain> |
DNSクエリ |
resolvectl flush-caches |
DNSキャッシュのクリア |
出力のサンプルを以下に貼ります。
resolvectl
resolvectl domain
resolvectl dns
resolvectl query google.com
resolvectl flush-caches
(参考) resolvectlによる設定変更
resolvectlによって、DNSサーバやsearchを動的に変更することもできます。
ただ、後述のとおり、恒久的な設定変更にはあまり向かない印象です。
構文は以下のとおりです。
resolvectl dns LINK [SERVER...]
resolvectl domain LINK [DOMAIN...]
resolvectl revert LINK
Fedora35における実行例を示します。
以下の変更を行っています。
- enp7s0に
192.168.100.2と192.168.100.3というDNSサーバを設定する
- enp7s0に
endy1.testとendy2.testというドメインに対するper-link DNSを設定する
以下のコマンド出力を見るとわかりますが、resolvectlで行った設定変更はNetworkManagerには伝搬していないようです。
man resolvectlによると、「resolvectl dnsやresolvectl domainによる変更はsystemd-resolvedとsystemd-networkdに伝わる」とあるので、NetworkManagerに通知されないのは不具合ではなく仕様かもしれません。
resolvectl dns
resolvectl domain
nmcli conn show enp7s0 | grep ipv4.dns
sudo resolvectl dns enp7s0 192.168.100.2 192.168.100.3
sudo resolvectl domain enp7s0 endy1.test endy2.test
resolvectl dns
resolvectl domain
nmcli conn show enp7s0 | grep ipv4.dns
上記変更を元に戻します。
resolvectl dns
resolvectl domain
上記の挙動は概ね良いのですが、NetworkManagerに設定変更が伝搬していないのが気になりました。
そこで設定変更後にOS再起動して、どうなるか確認してみました。
OS再起動後はresolvectl dnsの設定は残っていましたが、resolvectl domainの設定は消えてしまいました。
挙動としてはnmcliと比較してわかりづらいので、resolvectlによる設定変更を使うことは今のところ無さそうです。
revertコマンドが便利なので、一時的な検証用途であれば使ってみても良いかもしれません。
Network Manager経由 (nmcli) で設定した場合にはOS再起動で消えなかったので、基本的にはnmcliを使うのが良いかなという印象です。
(参考) D-Bus関連コマンド
D-Bus周りでそれっぽいコマンドを実行してみました。
D-Busに対応しているプロセスであれば、CLIやGUIだけでなくD-Bus APIでもステータスを確認できます。
--xmlオプションをつければ、XMLで出力することも可能です。
オブジェクトパス (/org/freedesktop/NetworkManager/DnsManager) はインターネットで「NetworkManager D-Bus」で調べても良いですが、bash-completion の働きでタブ補完することでも簡単に確認できました。
D-Bus オブジェクトにはプロパティとメソッドが紐付いて定義されており、コマンドラインで参照できます。
中々使う機会はないのですが、こういったものも存在することを知っておくとたまに便利かもしれません。
gdbus introspect --system --dest org.freedesktop.NetworkManager --object-path /org/freedesktop/NetworkManager/DnsManager
まとめ
具体例を入れたら非常に長くなってしまいましたが、systemd-resolvedの挙動についてまとめました。
D-Busの働きにより、NetworkManagerの設定変更によりsystemd-resolvedの設定を変更できるので、使い勝手は従来と大きく変わりません。
一方でVPNを利用している場合など、宛先ドメインによってDNSサーバを使い分けたいときにはsystemd-resolvedの per-link DNS 機能が役に立ちそうです。









{kind=link}