sudo useradd endy2
# [sss_cache] [sysdb_domain_cache_connect] (0x0010): DB version too old [0.22], expected [0.23] for domain implicit_files!# Higher version of database is expected!# In order to upgrade the database, you must run SSSD.# Removing cache files in /var/lib/sss/db should fix the issue, but note that removing cache files will also remove all of your cached credentials.# Could not open available domains# [sss_cache] [sysdb_domain_cache_connect] (0x0010): DB version too old [0.22], expected [0.23] for domain implicit_files!# Higher version of database is expected!# In order to upgrade the database, you must run SSSD.# Removing cache files in /var/lib/sss/db should fix the issue, but note that removing cache files will also remove all of your cached credentials.# Could not open available domains
id endy2
# uid=1001(endy2) gid=1002(endy2) groups=1002(endy2)
sudo userdel -r endy2
# [sss_cache] [sysdb_domain_cache_connect] (0x0010): DB version too old [0.22], expected [0.23] for domain implicit_files!# Higher version of database is expected!# In order to upgrade the database, you must run SSSD.# Removing cache files in /var/lib/sss/db should fix the issue, but note that removing cache files will also remove all of your cached credentials.# Could not open available domains# [sss_cache] [sysdb_domain_cache_connect] (0x0010): DB version too old [0.22], expected [0.23] for domain implicit_files!# Higher version of database is expected!# In order to upgrade the database, you must run SSSD.# Removing cache files in /var/lib/sss/db should fix the issue, but note that removing cache files will also remove all of your cached credentials.# Could not open available domains
virsh pool-list
# Name State Autostart# ----------------------------------------------# default active yes
virsh vol-list --pool default
# Name Path# -----------------------------------------------------# vm_name.qcow2 /home/shared/kvm_volumes/vm_name.qcow2
2番目の工程でパーティションを作成する際のパラメータ指定について補足です。 man fdiskに書いてあるように安全な方法でパラメータを指定します (Enter x2)。
First sectorはデフォルト値で指定することで、Alignmentの問題を踏まないようにしています。
Last sectorは単位 (MiB/GiB) を付けてサイズで指定するのが一般的ですが、今回は最終セクタを指定したいのでここもデフォルト値を使っています。
また、「Do you want to remove the signature? [Y]es/[N]o:」と聞かれる箇所がありますが、ここでは絶対にNoを選択してください。
間違えてYesを選択した場合は、writeをせず、落ち着いてqから抜けてください。
もしYesを選択した上でwriteしてしまうと、/dev/vda3のパーティションタイプがLinux LVMであるという情報が消えてしまいます。
結果として、次のPV拡張の工程でpvdisplayなどを実行しても何も表示されず、pvresizeコマンドも失敗してしまいます。
※既存のデータを全て削除して問題ない場合はYesでも良いのですが...
systemctl start sshd
# Job for sshd.service failed because the control process exited with error code.# See "systemctl status sshd.service" and "journalctl -xe" for details.
journalctl -e# Nov 12 08:11:34 my-vm /etc/ssh/sshd_config: No such file or directory
pvdisplay
# (出力なし)
pvcreate --uuid"BPTO1p-dz0e-gM36-37ls-nGY0-cUeD-Zcmt4b"--restorefile my_vm /dev/vda3 -t# TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.# WARNING: Couldn't find device with uuid BPTO1p-dz0e-gM36-37ls-nGY0-cUeD-Zcmt4b.# Physical volume "/dev/vda3" successfully created.
成功しました。
PVの状態を確認します。
PE Sizeなどが0になっていますが、これはVG作成前であるためなので気にしないで大丈夫です。
# "/dev/vda3" is a new physical volume of "18.41 GiB"# --- NEW Physical volume ---# PV Name /dev/vda3# VG Name # PV Size 18.41 GiB# Allocatable NO# PE Size 0 # Total PE 0# Free PE 0# Allocated PE 0# PV UUID BPTO1p-dz0e-gM36-37ls-nGY0-cUeD-Zcmt4b
vgdisplay
# (出力なし)
lvdisplay
# (出力なし)
vgcfgrestore -f my_vm my_vm -t# TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.# Restored volume group my_vm.
テストモード実行は問題なく通りました。 -tオプションを外して実行し、実際に復旧させます。
vgcfgrestore -f my_vm fedora_cinnamon
# Restored volume group fedora_cinnamon.
sudo pvdisplay
# --- Physical volume ---# PV Name /dev/vda3# VG Name fedora_my_vm# PV Size 18.41 GiB / not usable 2.00 MiB# Allocatable yes # PE Size 4.00 MiB# Total PE 4713# Free PE 41# Allocated PE 4672# PV UUID BPTO1p-dz0e-gM36-37ls-nGY0-cUeD-Zcmt4b
では、pvresizeでPVサイズを拡張します。
pvresizeのSyntaxは以下の構造です。
pvresize <pv-name>[options...]
オプションは多数ありますが、代表的なものは以下の通りです。
オプション
意味
-t, --test
実際に変更を行わず、想定結果のみ返して終了する
--setphysicalvolumesize Size
PVのサイズを指定する。 指定しない場合は自動認識する。 基本使わない
まずは、テストモードで実行してみます。
"1 physical volume(s) resized or updated" と出ているので、テスト実行としては成功しています。
sudo pvresize -t /dev/vda3
# TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.# Physical volume "/dev/vda3" changed# 1 physical volume(s) resized or updated / 0 physical volume(s) not resized
次は実際に変更します。
sudo pvresize /dev/vda3
# TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.# Physical volume "/dev/vda3" changed# 1 physical volume(s) resized or updated / 0 physical volume(s) not resized
sudo vgdisplay
# --- Volume group ---# VG Name my_vm# System ID # Format lvm2# Metadata Areas 1# Metadata Sequence No 4# VG Access read/write# VG Status resizable# MAX LV 0# Cur LV 2# Open LV 2# Max PV 0# Cur PV 1# Act PV 1# VG Size 23.41 GiB# PE Size 4.00 MiB# Total PE 5993# Alloc PE / Size 4672 / 18.25 GiB# Free PE / Size 1321 / 5.16 GiB# VG UUID RTiZsE-pO7c-2rMe-O5So-h2FA-PcFk-gz3wSi
sudo lvextend -t-r-l +100%FREE /dev/my_vm/root
TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.
Size of logical volume my_vm/root changed from 16.25 GiB (4160 extents) to 21.41 GiB (5481 extents).
Logical volume my_vm/root successfully resized.
sudo lvextend -t-r-l +100%FREE /dev/my_vm/root -v
TEST MODE: Metadata will NOT be updated and volumes will not be (de)activated.
Converted 100%FREE into at most 1321 physical extents.
Executing: /usr/sbin/fsadm --dry-run--verbose check /dev/my_vm/root
fsadm: "ext4" filesystem found on "/dev/mapper/my_vm-root".
fsadm: Skipping filesystem check for device "/dev/mapper/my_vm-root" as the filesystem is mounted on /
/usr/sbin/fsadm failed: 3
Test mode: Skipping archiving of volume group.
Extending logical volume my_vm/root to up to 21.41 GiB
Size of logical volume my_vm/root changed from 16.25 GiB (4160 extents) to 21.41 GiB (5481 extents).
Test mode: Skipping backup of volume group.
Logical volume my_vm/root successfully resized.
Executing: /usr/sbin/fsadm --dry-run--verbose resize /dev/my_vm/root 22450176K
fsadm: "ext4" filesystem found on "/dev/mapper/my_vm-root".
fsadm: Device "/dev/mapper/my_vm-root" size is 17448304640 bytes
fsadm: Parsing tune2fs -l"/dev/mapper/my_vm-root"
fsadm: Resizing filesystem on device "/dev/mapper/my_vm-root" to 22988980224 bytes (4259840 ->5612544 blocks of 4096 bytes)
fsadm: Dry execution resize2fs /dev/mapper/my_vm-root 5612544
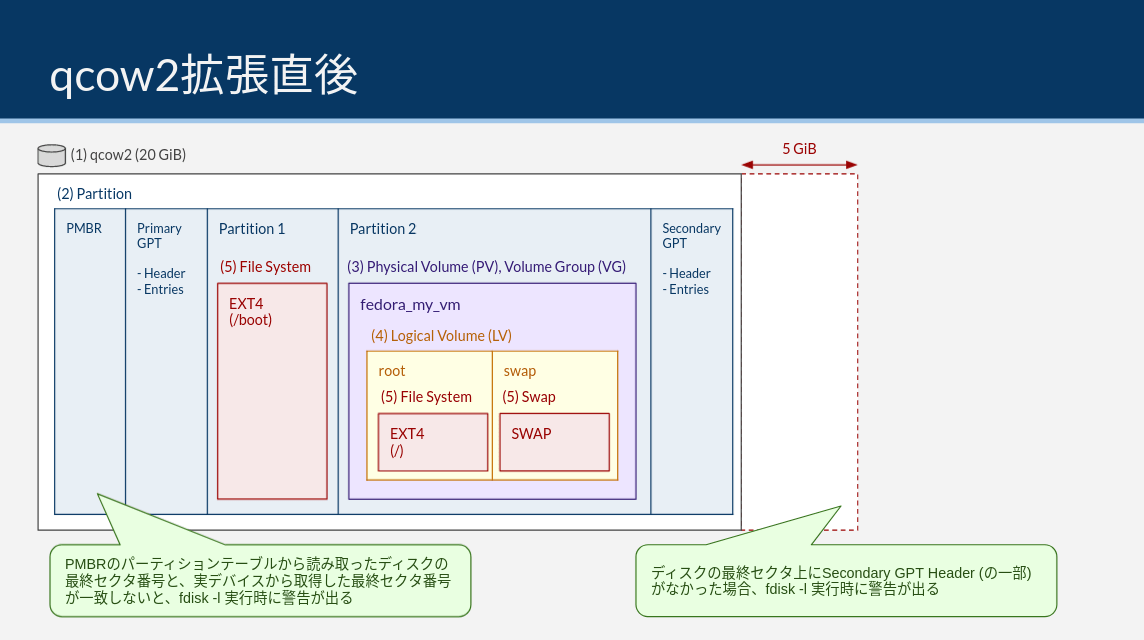
# GPT PMBR size mismatch (41943039 != 52428799) will be corrected by write.# The backup GPT table is not on the end of the device. This problem will be corrected by write.
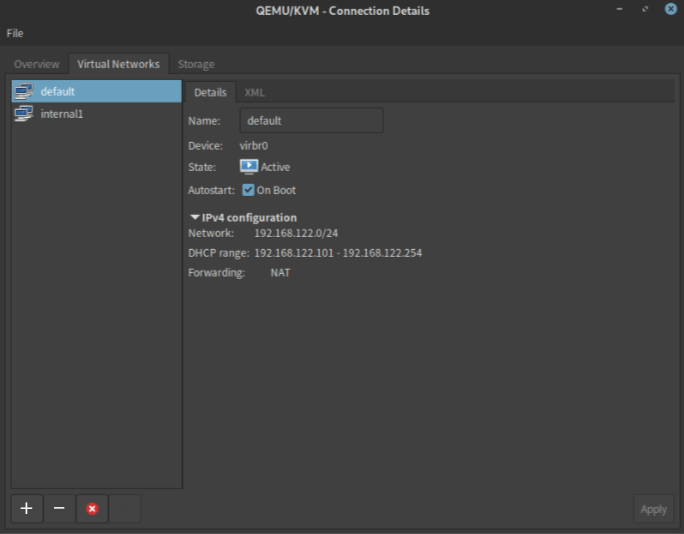
virsh net-list --all# Name State Autostart Persistent# ----------------------------------------------# default active yes yes# internal1 active yes yes
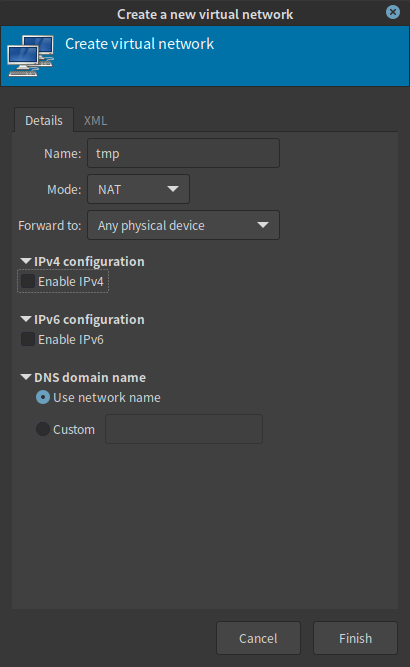
virsh net-list --all# Name State Autostart Persistent# ----------------------------------------------# default active yes yes# internal1 active yes yes# tmp active yes yes
virsh net-destroy tmp
# Network tmp destroyed
virsh net-undefine tmp
# Network tmp has been undefined
削除後、tmpが表示されなくなることを確認します。
virsh net-list --all# Name State Autostart Persistent# ----------------------------------------------# default active yes yes# internal1 active yes yes
virsh net-dhcp-leases default
# Expiry Time MAC address Protocol IP address Hostname Client ID or DUID# ------------------------------------------------------------------------------------------------------# 2022-02-27 13:41:03 52:54:00:6c:54:c8 ipv4 192.168.122.127/24 stream9-1 01:52:54:00:6c:54:c8